Reconnaissance is the initial phase of cyber threat hunting, where hunters gather information about the network, systems, and potential vulnerabilities. This phase is critical in identifying potential entry points for attackers and understanding the attack surface. Effective reconnaissance involves analyzing network traffic, system logs, and endpoint data to identify anomalies and potential security gaps.
In this walkthrough, we will use the Splunk Boss of the SOC (BOTS) version 2 dataset, which provides a simulated enterprise network environment with machine data from various sources. This dataset allows us to practice threat hunting in a realistic and controlled environment.
Let’s begin!
Be sure that you are logged into Splunk’s demonstration server at https://apthunting.splunk.show
Use the below credentials:
- Username: user001-splk
- Password: Splunk.5
Scenario
We have received a warning of an active campaign targeting our industry. We need to investigate the potential impact on our organization using the provided threat intelligence.
- The adversary is using a non-standard browser to scan public-facing web servers.
Based on the warning we received, we should begin our threat hunt by using Splunk to search for instances of non-standard browsers. A non-standard browser is a browser that is not commonly used, ie; A browser that is not Chrome, Firefox, Safari, MS Edge, ect.
Step 1 : Exam the sourcetypes we have to work with by following the below steps.
- Type this command into the Splunk search field:
| metadata type=sourcetypes index=botsv2 - Set the date and time for All Time.
- Scroll through the list of sourctypes and look for anything related to web traffic.
- Notice the sourcetype “stream:http”. This sourcetype is related to logs containing http traffic and requests, including website traffic. We will move forward in our threat hunt using the stream:http sourcetype.
Step 2: Review user-agent information in the stream:http logs
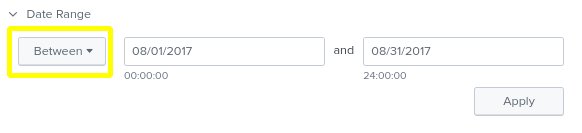
Threat intelligence suggests that our organization’s Frothly, was likely targeted by an attacker in August 2017, who performed reconnaissance scans on our website, www.froth.ly. Let’s set our date range in Splunk to August 1st 2017 through August 31st 2017 and follow the below steps to reveal the user-agent information for incoming web traffic to our website in the stream:http logs.
- Enter this command into the Splunk search field:
index=botsv2 sourcetype=stream:http - In the left column under interesting fields, we will see http_user_agents with 100 logged instances.
- Enter this command into the Splunk search field to reveal the user-agents that visited our website in August 2017 and the number of recorded occurrences, sorted by lowest to highest:
index=botsv2 sourcetype=stream:http site=”www.froth.ly” | stats count by http_user_agent | sort + count - As we scan the recorded user-agents information, we should notice an instance from a Fedora Linux operating system and an unusual browser named “NaenarBrowser”.
- Visit the website https://explore.whatismybrowser.com/useragents/parse/#google_vignette
- In the above website, paste the entire user-agent string into the “Parse a user-agent” field and click “Parse this user-agent” button.
- The parsed information confirms that this user-agent instance is coming from a Fedora Linux operating system and a Naenara browser.
- A Google search reveals that this Naenara browser is commonly used in North Korea, an adversary of the United State.
Step 3: Investigate the source IP address of the malicious user-agent
Even though in step 2 we learned that this user-agent is using a browser that is commonly used in North Korea, we should not assume that this attack is originating from North Korea. It could very well be another adversary or even someone inside the United States using spoofing techniques to throw us off his scent. Let’s try to confirm who this malicious actor really is by investigating the source IP address.
- Click the user-agent string in our previous search results and select New Search from the pop-up menu to add the string to our search query. It should look like this:
index=botsv2 sourcetype=stream:http site=”www.froth.ly” http_user_agent=”Mozilla/5.0 (X11; U; Linux i686; ko-KP; rv: 19.1br) Gecko/20130508 Fedora/1.9.1-2.5.rs3.0 NaenaraBrowser/3.5b4″ - Add a stat count by source to destination ip command to the query so the entire search query now looks like this:
index=botsv2 sourcetype=stream:http site=”www.froth.ly” http_user_agent=”Mozilla/5.0 (X11; U; Linux i686; ko-KP; rv: 19.1br) Gecko/20130508 Fedora/1.9.1-2.5.rs3.0 NaenaraBrowser/3.5b4″
| stats count by src dest
This search query is searching the botsv2 index’s webserver logs for traffic accessing our website from the suspicious user-agent and revealing the IP addresses associated with that user-agent. - The results of the above search query reveal source IP address 85.203.47.86 has connected to our website (dest IP 172.31.6.251 is us).

- We will now create a free account on IPinfo.io to further investigate the IP address 85.203.47.86.
- Log into IPinfo.io with our new account and enter the IP address, 85.203.47.86 into the search field on the top. The results will be displayed immediately without clicking a search button.
- As we scroll down and review the information, we will notice the service “ExpressVPN”. This well-known service allows users to mask their location, making it difficult to determine their true origin.
Step 4: Determining what information was accessed by the malicious actor.
Since we are unable to confirm the location of IP address of the user-agent, we will move on to the next step of our investigation to determine if the threat-actor was able to access any sensitive information.
- Using the previous query from Step 3, look at the Interesting Fields column for fields that might reveal what content the user-agent accessed.
index=botsv2 sourcetype=stream:http site=”www.froth.ly” http_user_agent=”Mozilla/5.0 (X11; U; Linux i686; ko-KP; rv: 19.1br) Gecko/20130508 Fedora/1.9.1-2.5.rs3.0 NaenaraBrowser/3.5b4″ - In the Interesting Fields column on the left, notice “http_content_type”. This is the field in the log that tells us the type of data being transferred from our service. Click it to open the pop-up window.
- When we exam the values of the http_content_type we know that it’s common for images, text/html files and javascript to be access in a website, but it is less common for spreadsheet to be accessed on a website.
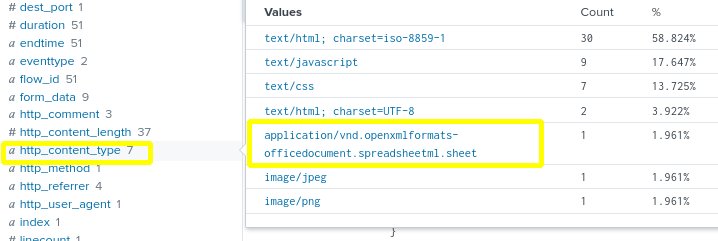
- Click the spreadsheet value to add it to our search query.
- Reviewing the first entry of the new search query, we see the url path of the spreadsheet is /files/company_contacts.xlsx, indicating that a spreadsheet named company_contacts.xlsx was accessed.

- Add a table command to the search query to reveal complete information by adding this to the end of the previous query:
| table _time, src, dest, uri_path, url

At the end of this investigation we learned that a threat-actor using a non-standard North Korea web-browser and ExpressVPN to disguise his IP address as coming from North Korea probed our website looking for unsecured sensitive information. The threat-actor discovered and downloaded an unsecured spreadsheet called “company_contacts.xlsx”. We can assume that the threat-actor will now use the spreadsheet containing contact information of company employees to conduct a sophisticated spear-phishing campaign and try to infiltrate our systems on a deeper level. We must take steps to tighten security on our network infrastructure and prepare for the next stages of this cyber-attack.